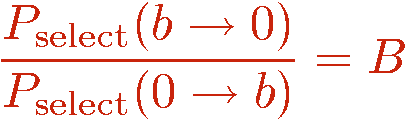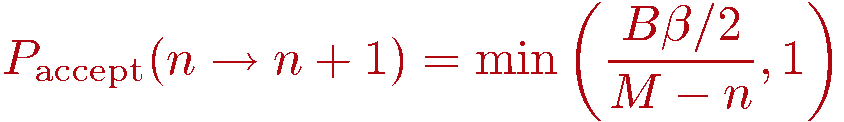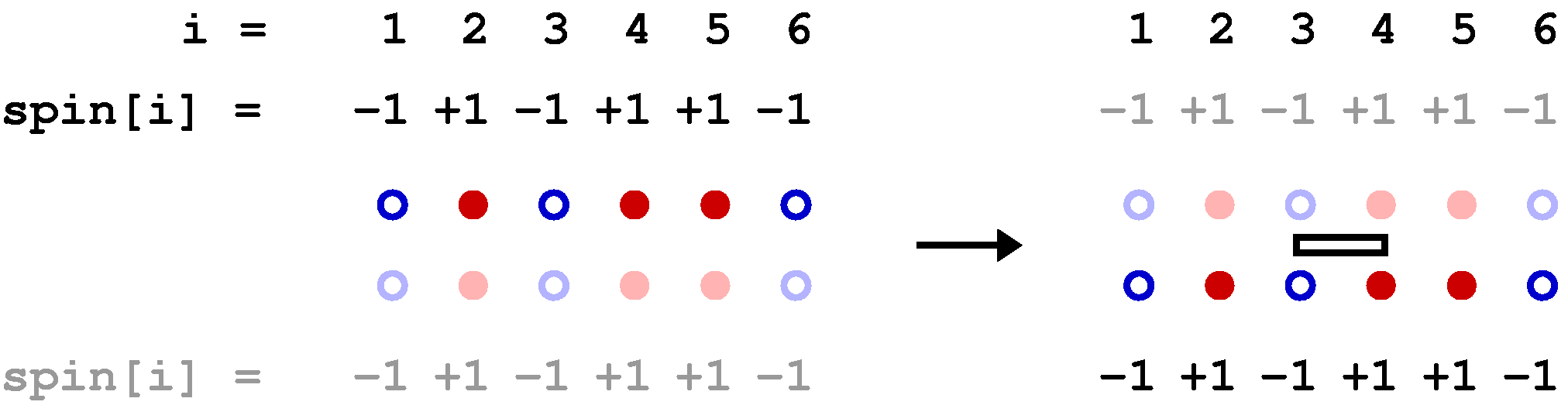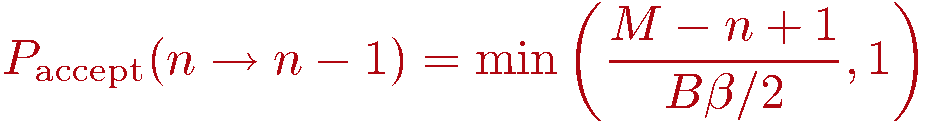In writing this tutorial I have assumed that the reader understands the basic principles of Monte Carlo simulations, e.g., of the classical Ising model. Some knowledge of quantum statistical mechanics and the Heisenberg model is also assumed. Apart from this, the exposition is self-contained. The technical description of the algorithm is more detailed than in published papers; the target audience is beginning graduate students or advanced undergraduates, but hopefully this kind of detailed account will be useful also for more seasoned researchers wishing to learn the method quickly.
The general principles of the SSE method are summarized in Sec. 1). In Sec. 2) the implementation of the algorithm for the S=1/2 Heisenberg model is discussed. The main data structures used in the program ssebasic.f90 are introduced at this stage and they way they are manipulated is discussed. Estimators for various expectation values are discussed in 3). The actual computer program is described in detail Sec. 4). Instructions on how to run the program (which is extremely easy) are given in Sec. 5).
1) General principles of the SSE method
1.1) A classical example
As a warm-up before considering the SSE method for solving quantum statistical mechanics problems, we first look at a classical analogue, which will provide a simpler framework for giving insights into some of the key aspects of the method. Consider a classical thermal expectation value
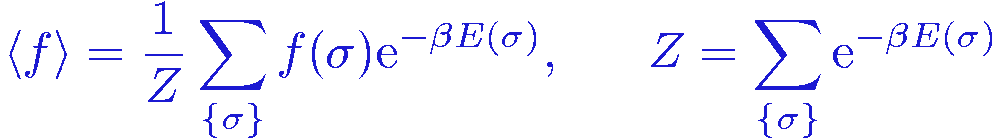
where &sigma includes all the degrees of freedom of the system, e.g., the spin configurations of an Ising model; &sigma={&sigma1,&sigma2,...,&sigmaN} , E(&sigma) is the energy, and &beta=1/T is the inverse temperature (using dimensionless units).
We can evaluate this expectation value using the standard Monte Carlo method, where the configurations are importance sampled, using e.g., the Metropolis algorithm, according to the Boltzmann probability distribution,
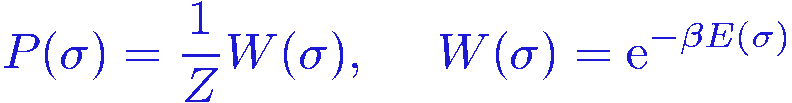
The expectation value is then simply obtained as the average of the function f(&sigma) over the sampled configurations &sigma[i], i=1,...,Nsamples
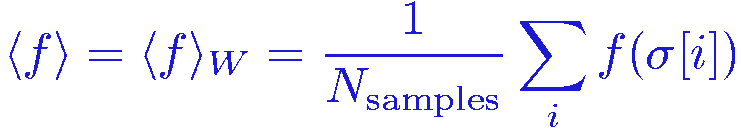
Imagine now that we are not able to evaluate the exponential function. If we are able to evaluate any power of a number, we could Taylor expand the exponential and write the expectation value as
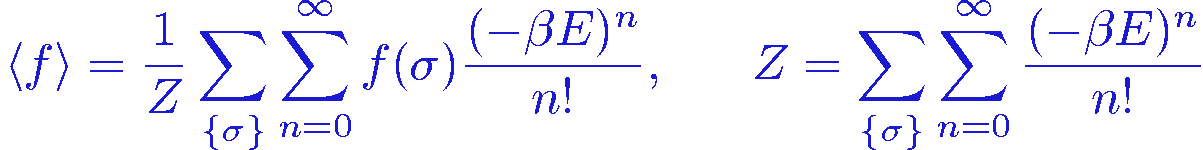
We can think of this as having enlarged our configuration space into an "expansion dimension" where the coordinate to be sampled is the power n. We can thus carry out a Monte Carlo sampling in the configuration space {(&sigma,n)}. This would work provided that all the terms in the sum are positive, which would require the energy to always be negative. This would normally not be the case, but we can always subtract a constant &epsilon from the energy without changing the physics. With a thus suitably chosen constant &epsilon>0, the weight to be used for sampling the extended configuration space is
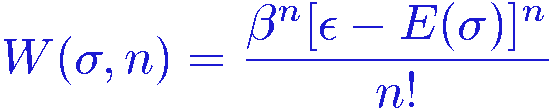
Let's now look at some particular expectation values. The estimator f(&sigma) to be averaged is some function of the original state variables, which does not depend on the expansion power n. However, if f(&sigma) is a function of the energy it turns out that one can rewrite the estimator into a function of only n! To simplify the notation we define H=&epsilon-E.
Let's look at the expectation value <
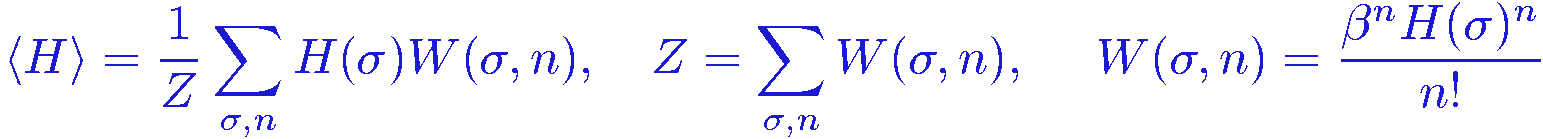
By shifting the summation index to m=n+1 in the first sum, it is now easy to see that we can rewrite it as
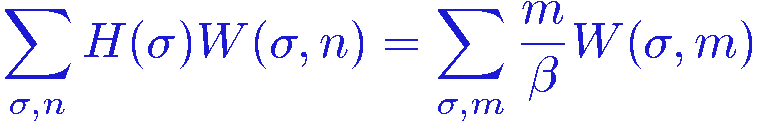
and we can therefore write the expectation value as
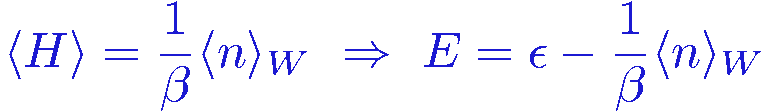
and so indeed we only have to keep track of the expansion power n in order to evaluate the energy. Although a simple result, this is quite remarkable! Of course we still have to deal with the variables &sigma when sampling the configurations.
Let's also calculate the expectation value of H2. Proceeding as above, writing the sum over n of H2W(&sigma,n) in terms of a shifted summation index k=n+2, we get
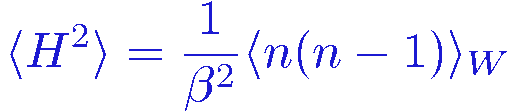
and since the heat capacity
C = ( <
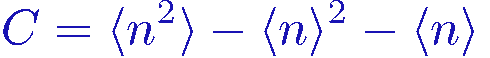
The above expressions for E and C in terms of n are also useful for understanding what expansion powers can be expected to dominate in the sampling. From the expression for the energy E we get the average expansion power

Since &epsilon-E(&sigma) is positive for all states &sigma this expectation value is of course always positive by construction.
Using the expression for C and E together with the above equation we get the variance
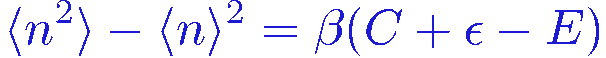
Normally C vanishes as the temperature is taken to zero and then we can write the variance as

Since the energy is proportional to the system size N, we can deduce that at low temperarures the average expansion power is proportional to N/T and the width of the distribution is the square-root of the average length. As we shall see, these results will hold true also in the quantum mechanical case.
1.2) Quantum mechanical SSE
In quantum statistical mechanics we are interested in calculating the expectation value of some operator A at temperature T for some model hamiltonian H;
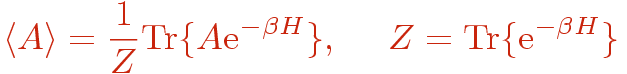
where &beta=1/T and we will work in units where all constants of nature are set to unity. The problem here is how to evaluate the exponential function of the hamiltonian, which in cases of interest contains non-commuting operators. In the SSE method the exponential operator is taken care of by a Taylor expansion and the trace is expressed as a sum over a complete set of states in asuitable chosen basis;
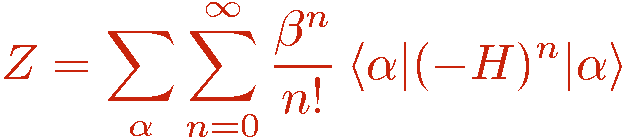
The hamiltonian of interest is written as
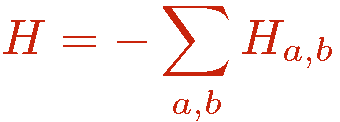
where the indices a and b refer to an operator class or type, e.g., diagonal (a=1) or off-diagonal (a=2) in the chosen basis and a lattice unit, e.g., a bond b connecting a pair of interacting sites i(b),j(b). Tthere can in principle be several types of diagonal and off-diagonal operators; the index a then takes more than two values. The powers of the hamiltonian are written as a sum over all possible products ("strings") of the operators Hab;
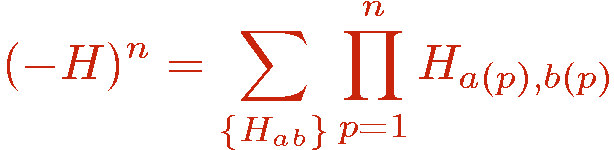
The operators Hab do not all commute with each other. The order of the operators in the string is therefore important.
It is convenient not to have to deal with strings of varying length n. Therefore, an identity operator 1 that is not part of the hamiltonian is also introduced and written using the same notation as for the terms of the hamiltonian, with indices a=b=0;
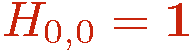
The Taylor expansion is truncated at some cut-off M which is chosen (automatically by the program) sufficiently large for the truncation error to be exponentially small and completely negligble (which can be shown to require M proportional to &beta|E|, where E is the total internal energy). The unit operator H0,0 is used to augment all strings with n < M. Allowing for all possible placements of unit operators in the string we have
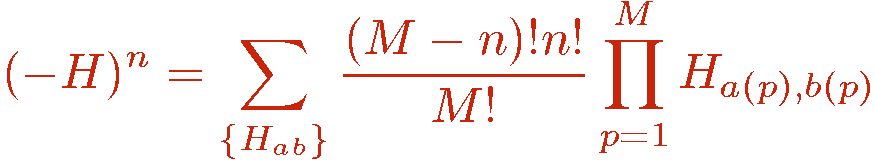
where n now denotes the number of hamiltonian operators in the string, i.e., the operators with non-zero a and b. It should be noted that the truncation of the expansion is not necessary in principle. Simulations can also be done with fluctuating string lengths with no upper bound on n. The importance sampling would then anyway ensure that the range of expansion powers n is finite in practice, because the weight above some power, n>M, is exponentially small and would never be sampled (during the life time of the simulator, or even of the universe). Thus the truncation should not be seen as an approximation. It is introduced as a means for slightly simplifying the sampling scheme. The starting point of the SSE algorithm is thus normally the partition function written as
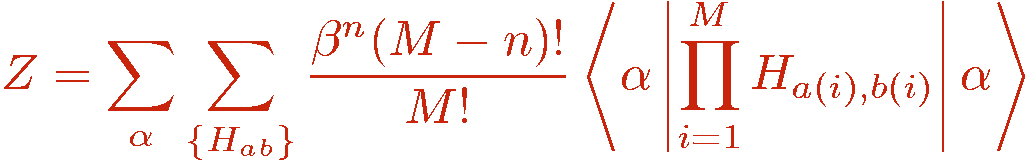
and a similar expression including the operator A in front of the product. In a Monte Carlo simulation, the SSE terms (&alpha,{Hab}) are sampled according to their weight in the above partition function summation. This requires that all terms are positive, so that they can be used as relative probabilities. The presence of negative terms is referred to as the sign problem. In principle the series can be sampled even with a sign problem, by using the absolute value of the weight and later correcting for the error made, but in practice such simulations are limited to very small lattice sizes. Fortunately there are several classes of interesting hamiltonians for which positive definitness can be achieved.
2) SSE algorithm for the S=1/2 Heisenberg model
The Heisenberg hamiltonian is
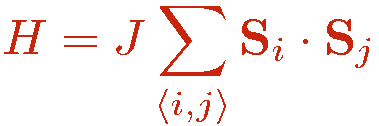
where we assume here that there are interactions only between nearest-neighbor spins, pairs of which are denoted as i,j and we consider the antiferromagnetic case; J>0. The SSE method is by no means restricted to this case, but in order for the expansion to be positive definite (i.e., to avoid the Monte Carlo "sign problem") the lattice has to be bipartite (non-frustrated). A bipartite lattice/interaction is one for which one can divide the sites into two groups, A and B, such that all antiferromagnetic interactions are between sites in A and B. This is the case for the 2D square lattice (or a cubic lattice in any D) with nearest-neigbor interactions, for which the sublattices corresponds to the black and white squares of a checkerboard, as illustrated in the figure below with red and blue sites. A prototypical example of a non-bipartite (frustrated) lattice is the triangular lattice.

The program ssebasic.f90 is written for the 2D square lattice with N=Lx*Ly sites and periodic boundary conditions. Note that Lx and Ly both have to be even for this lattice to be bipartite.
We will use the standard basis of spins "up" and "down" along the z quantization axis. For a lattice with N spins (S=1/2) the basis states are thus

In this basis it is convenient to rewrite the hamiltonian using the z-component and ladder operators, and we also set the coupling J=1)
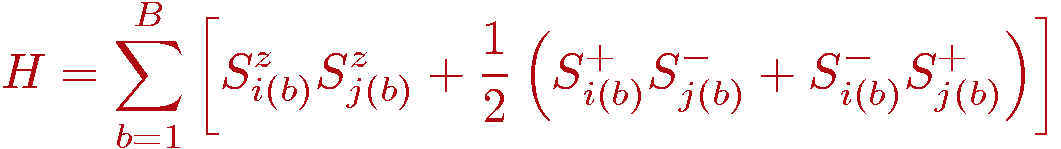
where we have also introduced the bond operator notation; b=1,...,B denotes a bond connecting two interacting spins i(b),j(b) and B is the number of bonds. For the 2D square lattice with periodic boundary conditions B=2N.
We now introduce the diagonal (a=1) and off-diagonal (a=2) bond operators
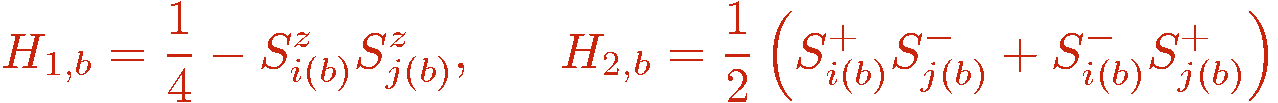
in terms of which the hamiltonian is
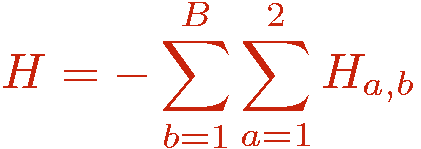
Here we have neglected a minus sign in front of the off-diagonal operators. This corresponds to a sublattice rotation, in which all the ladder operators are multiplied by -1 (or, equivalently, the x and y spin operators are rotated by 180 degrees) on one of the sublattices of a bipartite lattice. The sublattice transformation does not affect the commutation relations among the spin operators and hence the level spectrum of the hamiltonian does not change. Physical properties involving off-diagonal operators change only, at most, by a sign. The ability to carry out such a transformation is what enables a positive-definite expansion in the SSE method. For a non-bipartite lattice there will be both positive and negative terms in the expansion and the Monte Carlo sampling is then hampered by the sign problem. We will se below that the positive definitness for a bipartite lattice also follows automatically in the SSE method even without formally carrying out a sublattice rotation, i.e., we could equally well keep the minus sign of the off-diagonal operators and still obtain a positive definite expansion. We will anyway leave out the sign here to make the formulas a bit simpler. Thus the assumption here is always that we are dealing with a bipartite lattice. The reason for introducing the constant 1/4 in the diagonal bond operator also has to do with avoiding a sign problem, as will become clear below.
2.1) Representation of operators and states; SSE configurations
In the program the SSE operator products in the partition function,
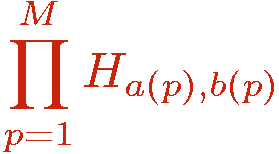
are represented by a one-dimensional integer array opstring[p], p=1,...,M, where both indices a and b are encoded into a single integer according to:

so that even and odd valued elements correspond to diagonal and off-diagonal operators, respectively. The non-hamiltonian identity operator (a=b=0) is naturally encoded as: opstring[p]=0.
The spin state |&alpha> of the system is represented by an array spin[i], i=1,...,N, with elements +1 and -1 corresponding to spin up and down, or
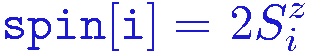
The bond index b corresponds to two interacting spins i(b),j(b), which in the program are stored in an array bsites(s,b), where s=1,2 corresponds to the two sites; bond b connects sites bsites[1,b] and bsites[2,b]. This list is the only information on the lattice geometry needed in the sampling of configurations. For the bond labeling, the program ssebasic.f90 defines the x-bonds in the range b=1,...,N and the y-bonds in b=N+1,...,2N. The sites with coordinates x=0,...,Lx, y=0,...,Ly on an Lx*Ly lattice are numbered as i=1+x+y*Lx, but this information does not have to be stored as it is not needed in the simulation. The coordinates can be needed in various measurements, but then they can easily be calculated on the basis of the site index i; x=mod(i-1,Lx), y=(i-1)/Lx. The labeling convention for sites and bonds for a 4*4 lattice are shown in the figure below.
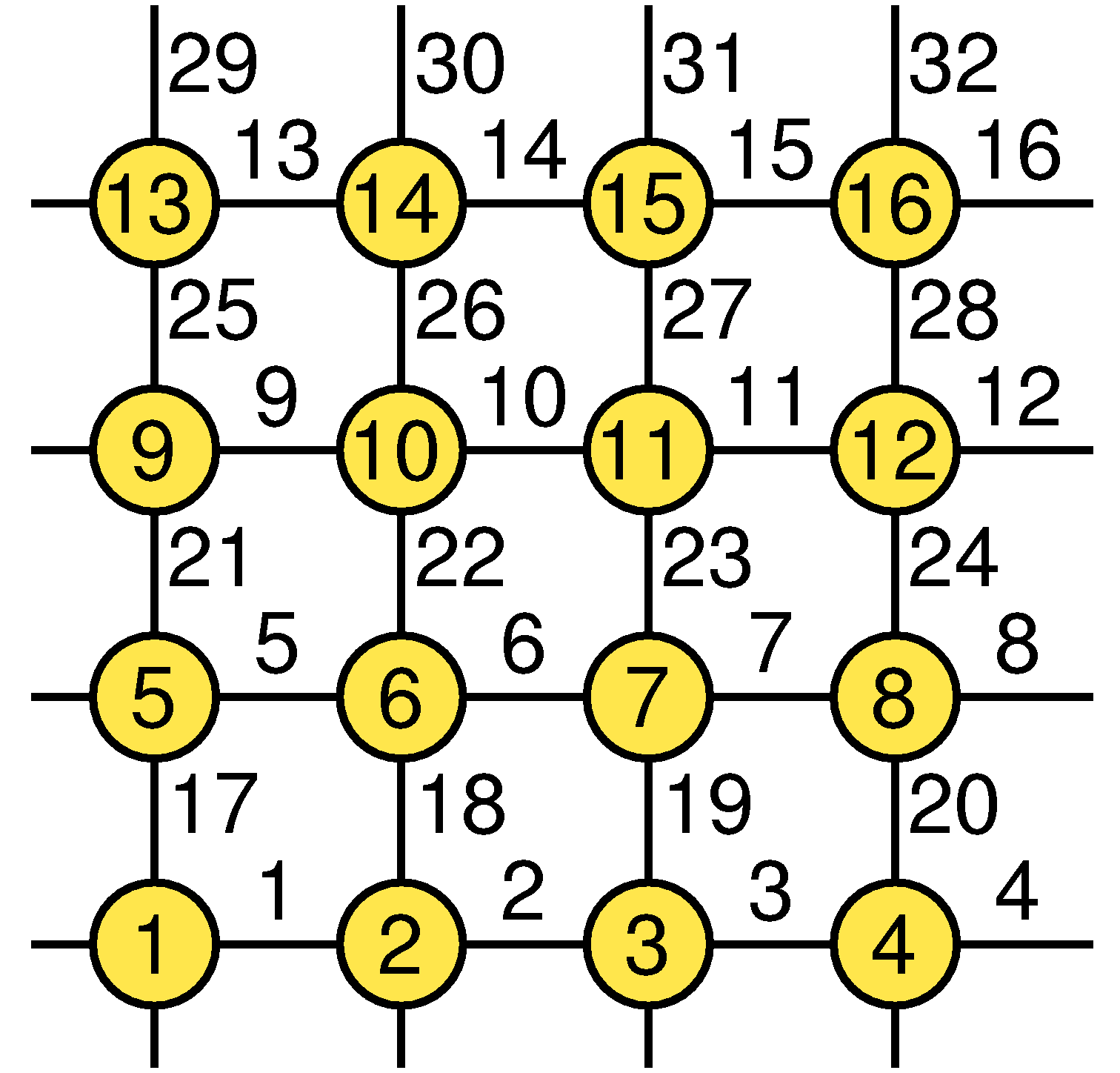
Thus bsites[1,1]=1,bsites[2,1]=2,...,bsites[1,4]=4,bsites[2,4]=1,..., bsites[1,17]=1,bsites[2,17]=5,...,bsites[1,32]=16,bsites[2,32]=4.
With the constant 1/4 included in the definition of the diagonal operator, both types of operators (diagonal and off-diagonal) can act only on anti-parallel spins, i.e., any operator acting on a pair of parallel spins leads to a configuration that does not contribute to the partition function. This is a key aspect of the SSE method for the isotropic S=1/2 Heisenberg model. Another key aspect is that all non-zero matrix elements of both diagonal and off-diagonal operators equal 1/2, so that the weight W of an allowed configuration (&alpha,{Ha,b}) is simply given by the number, n, of non-unit operators in the sequence;
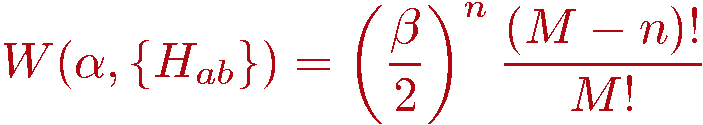
In the simulation the configurations are to be sampled with a probability proportional to this weight; P=W/Z. It is thus clear that a constant had to be added to the bond operator and that its minimum value is 1/4, in order to make W positive definite. The value 1/4 for the constant is particularly practical (exactly why will become clear later) because it disallows operation on parallel spins, which is also the case with the spin-flipping off-diagonal operators.
It is useful to define a propagated state |&alpha(p)> as the stored basis state |&alpha>=|&alpha(0)> propagated by the first p operators in the string;
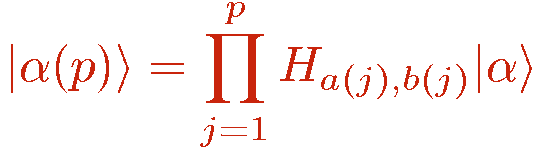
These states are of course also basis states. This is another key aspect of the SSE method; that the operators and basis have to be chosen such that propagating a basis state with an operator string leads to a sequence of single basis states, i.e., there is no branching of "paths".
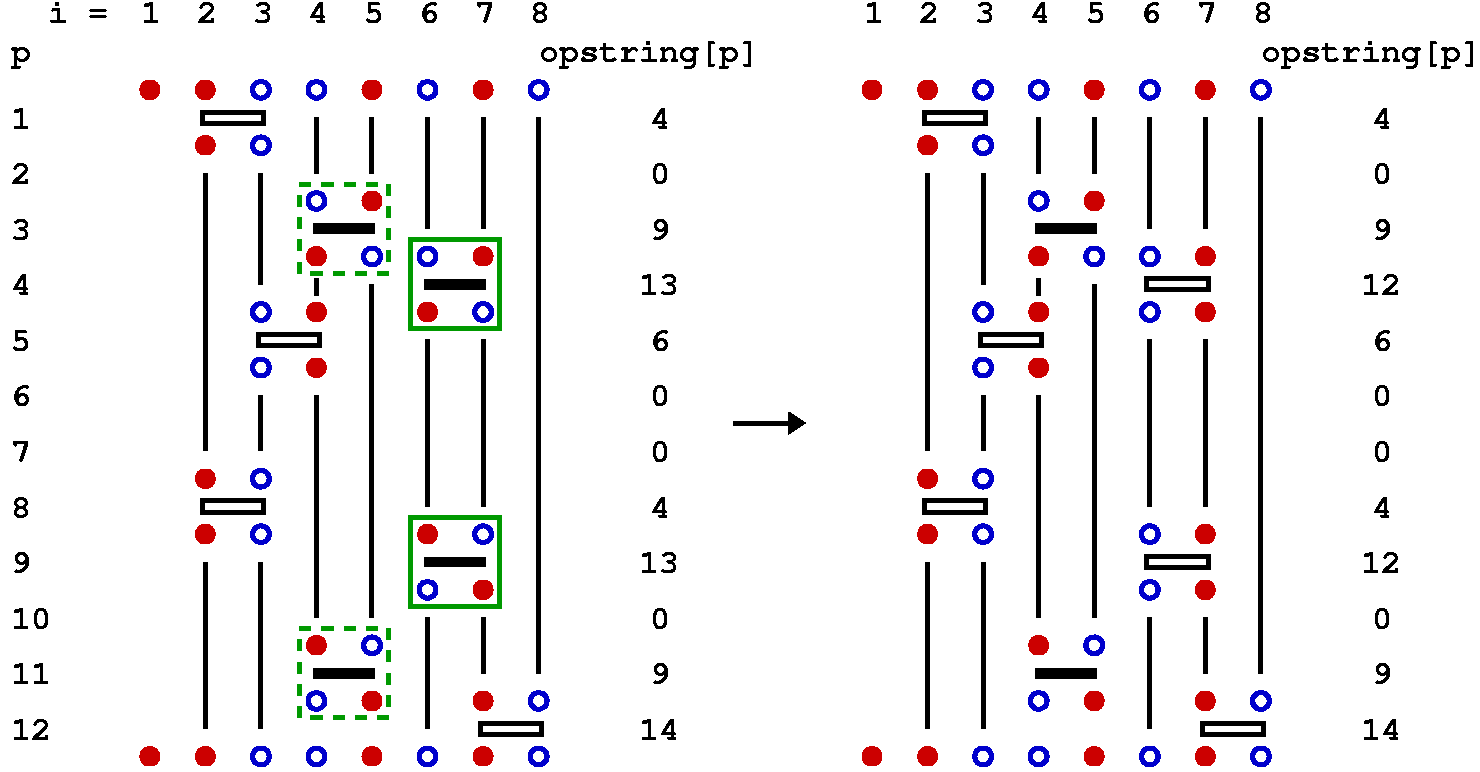
Below is a graphical representation of an SSE configuration for a 8-site one-dimensional chain, showing all the propagated states. Each row of red and blue circles corresponds to a state of spins up (red) and down (blue). The operators are represented by bars between the sites on which they act; open and solid bars for diagonal and off-diagonal operators, respecyively. In this case the expansion cut-off M=12, there are n=8 hamiltonian bond operators and, four (M-n=4) unit operators (a=b=0). The latter correspond to empty space between the states where these operators "act". The figure also shows the data structures stored in the computer, along with the indices a(p) and b(p), which are not stored but are easily obtained from the operator string when needed; a(p)=MOD(opstring[p],2)+1, b(p)=opstring[p]/2. The bond index b in this one-dimensional example equals the site label of the first spin connected by the bond, i.e., bond b is connected to sites b and b+1.
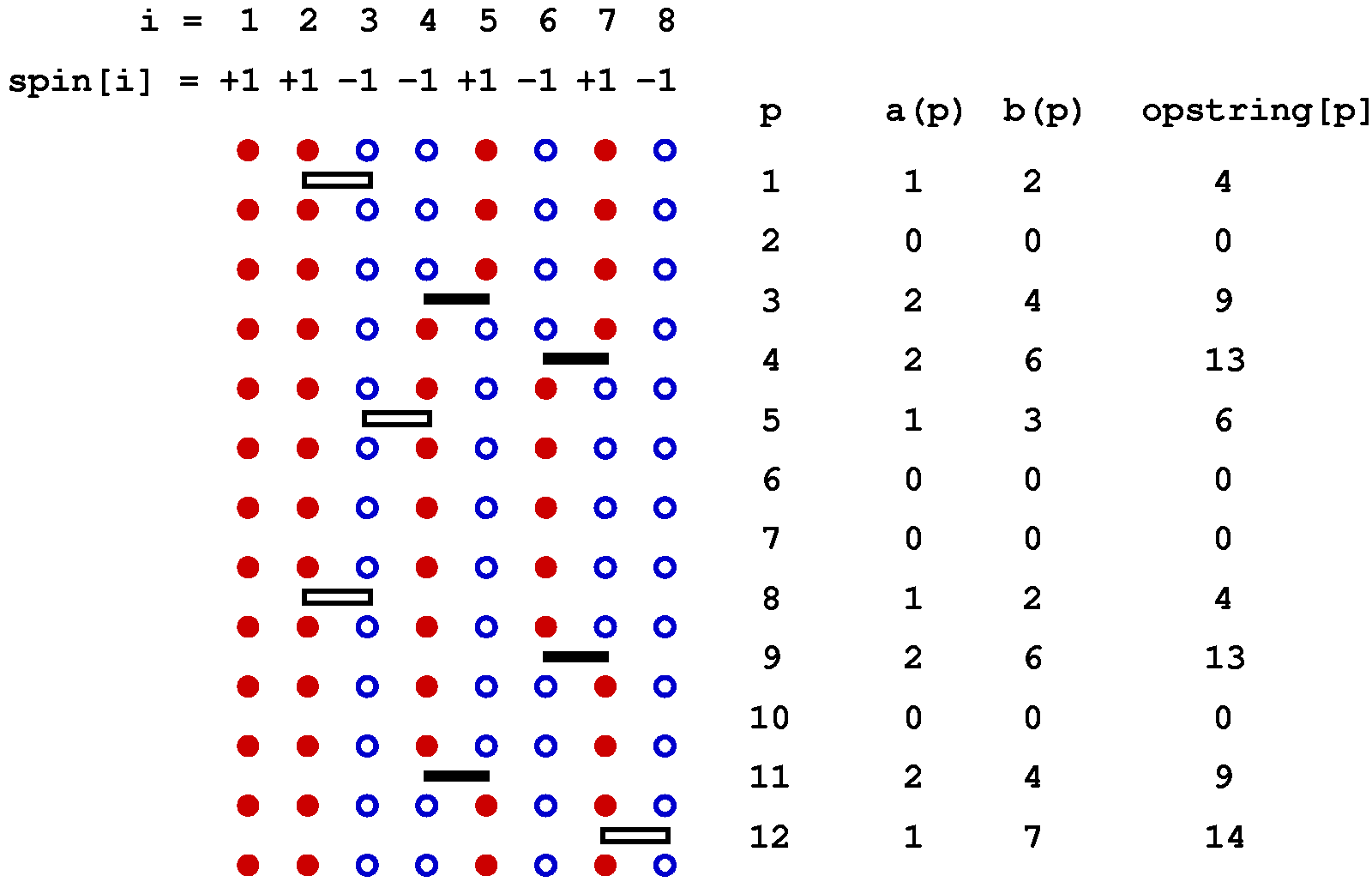
The propagated states are not stored in the program but are shown explicitly here in order to illustrate how the operator string propagates the state |&alpha> periodically, i.e., the boundary condition |&alpha(M)> = |&alpha(0)> = |&alpha> must be satisfied for a contributing configuration. This periodicity implies that each spin must be flipped an even number of times (or not at all) during the propagation from p=1 to p=N. This in turn implies that there has to be an even number of off-diagonal operators in the string. Thus, even if we had kept the minus sign in front of the off-diagonal operators, this sign would never show up because it would be raised to an even power in all allowed configurations. For a non-bipartite lattice this is no longer true, as sn odd number of oparators then can flip spins cyclically around a loop, in such a way that each spin is flipped twice and hence leaving the spins on the loop the same as before the propagation.
Clearly the vast majority of configurations do not satisfy the periodicity and hence do not contribute to the partition function. A requirement for an efficient sampling scheme for the configurations is that no attempts to change the configuration are carried out that violate the propagation periodicity.
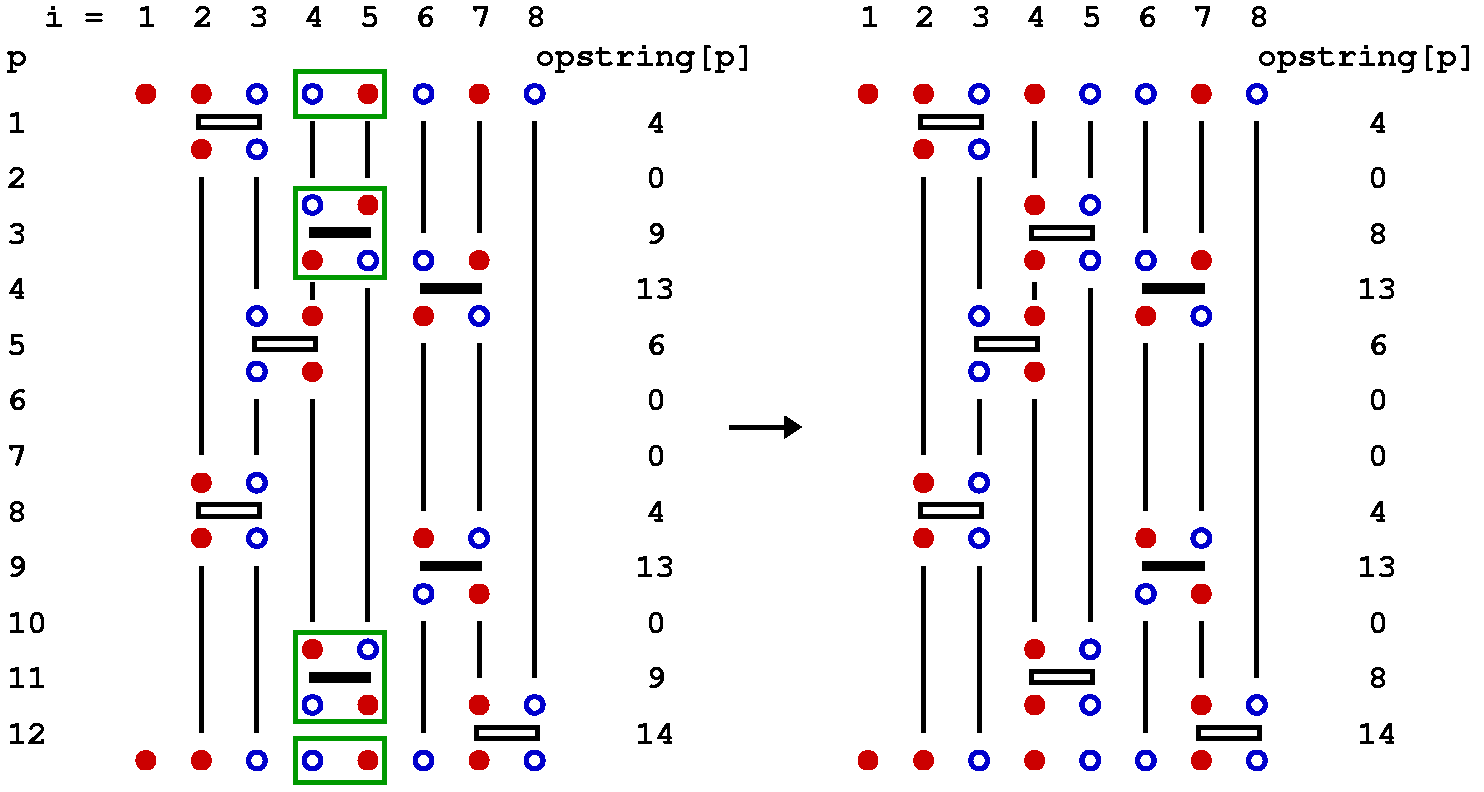
The representation of the current SSE configuration by the arrays spin[] and opstring[] is used throughout the program. From these, any propagated state can be generated as needed. In one part of the updating procedure another temporary representation of the configuration is used. This linked vertex representation captures directly the way the operators are "connected", i.e., using it one can directly jump from an operator at position p, which acts on two spins i(b(p)) and j(b(p)) (in the program bsites[1,opstring[p]/2] and bsites[2,opstring[p]/2) to the next or previous operator acting on one of these spins, without having to conduct a tedious search in the list opstring[]. Each bond operator acts on two "in" spins and the result of this operation is two "out" spins. In the linked vertex representation an an operator is represented by a vertex with four legs. Each leg has a corresponding spin state. There are four allowed vertices;

Here the bars between the spins are clearly redundant, but for illustrative purposes it is useful to keep them anyway.
A graphical representation of the linked vertices is obtained by removing from the propagated states in the full-configuration figure above the columns of fixed spins between consecutive operations. These spins are replaced by vertical lines, representing links between elements in a list kept in the program;
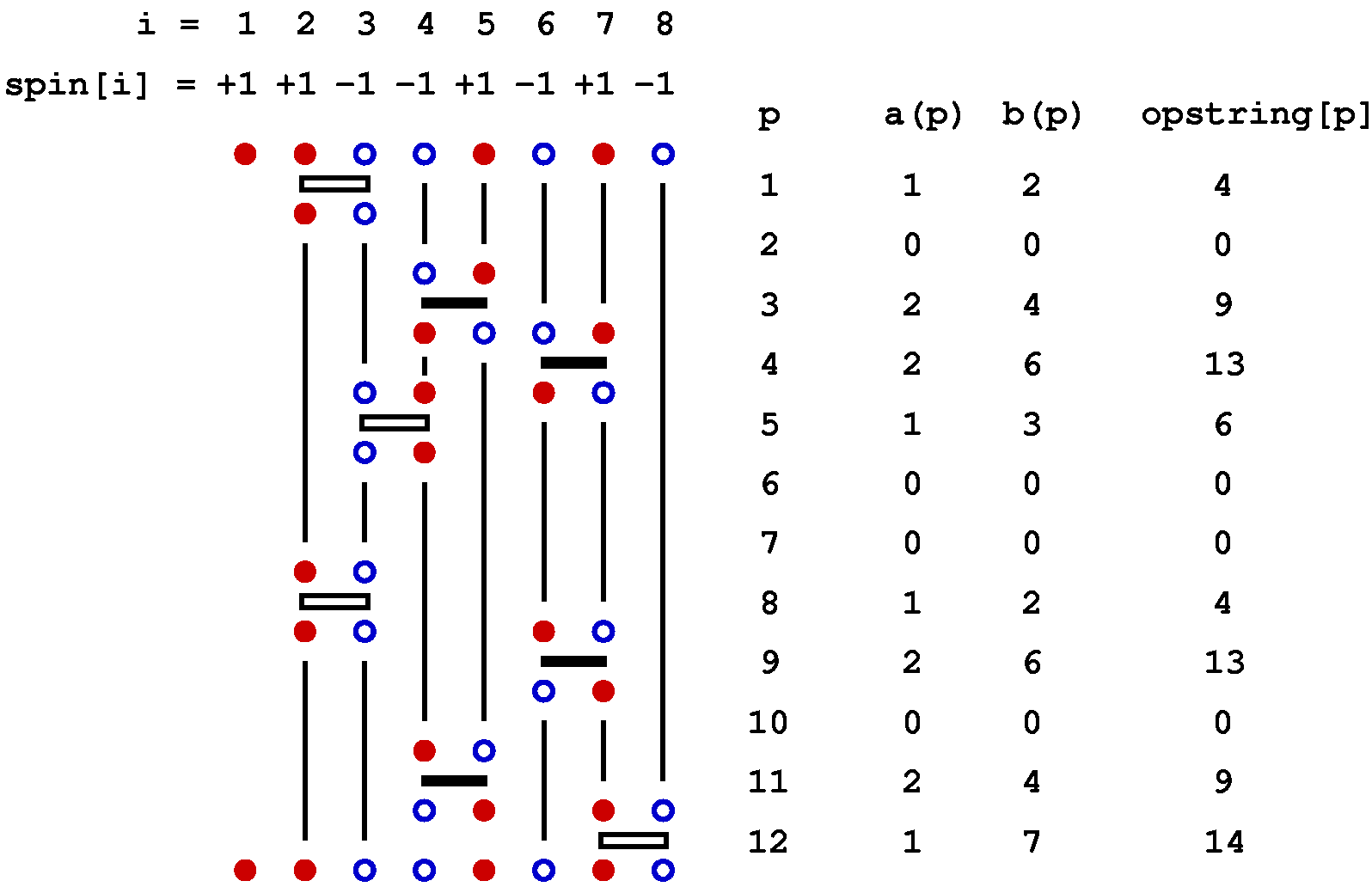
In the linked list one can move from any vertex leg to the next or previous leg sitting on the
same site or the other site on which the operator acts.
Each vertex can be identified by its position p in the list
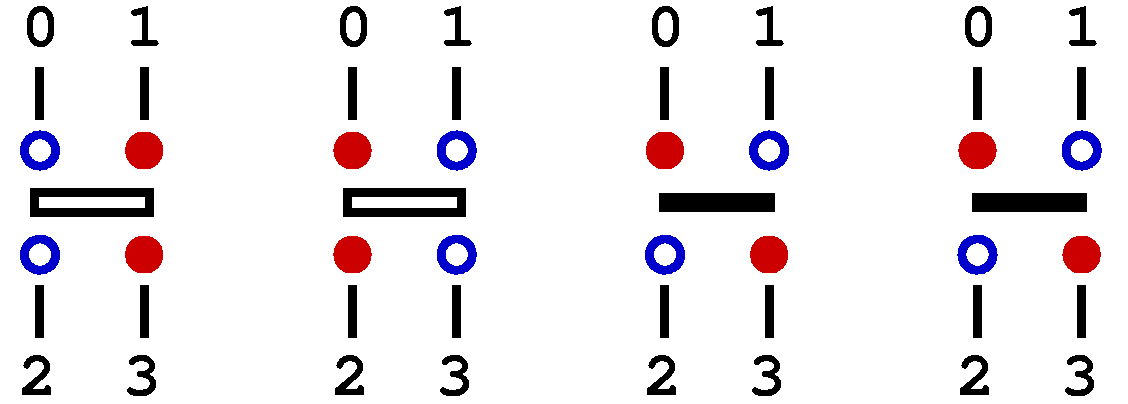
The linked list is a temporary data structure, to be used in one of the configuration updates. It is constructed before this update and destroyed after. The data structutes opstring[] and spin[] serve as permanent storage of the configuration. In the program, the link connecting vertex leg v is stored in a list vertexlist[v], v=1,...,4*M. Here we describe the contents of the list, deferring to the following section the discussion of how and why it is used. The procedures for constructing the linked list using the information in opstring[] and spin[] will be discussed in the program description, Sec. 4.
The list element vertexlist[v] contains the label (i.e., the position in vertexlist[])
of the vertex leg to which leg l=MOD(v,4) of vertex
p=1+(v-1)/4 is connected. The list is double-linked, so that one can
move both up and down. This implies that vertexlist[vertexlist[v]]=v.
For the configuration illsutrated above, the contents of the vertex list are,
Here the one-dimensional array has for convenience been arranged in four columns, with the
leg and vertex numbers corresponding to the positions v also indicated.
The positions corresponding to unit operators in
the string opstring[] are set to zero. Note the periodic boundary conditions of the links,
which imply that a leg can be linked to another leg of the same vertex, which is the
case in this list for legs 0 and 3 of vertex 12.
l = 0 1 2 3 p
[v] vertexlist[v]: [ 1] 31 [ 2] 32 [ 3] 29 [ 4] 17 1
[ 5] 0 [ 6] 0 [ 7] 0 [ 8] 0 2
[ 9] 43 [10] 44 [11] 18 [12] 42 3
[13] 35 [14] 47 [15] 33 [16] 34 4
[17] 4 [18] 11 [19] 30 [20] 41 5
[21] 0 [22] 0 [23] 0 [24] 0 6
[25] 0 [26] 0 [27] 0 [28] 0 7
[29] 3 [30] 18 [31] 1 [32] 2 8
[33] 15 [34] 16 [35] 13 [36] 45 9
[37] 0 [38] 0 [39] 0 [40] 0 10
[41] 20 [42] 12 [43] 9 [44] 10 11
[45] 36 [46] 48 [47] 14 [48] 46 12
2.2) Sampling the configurations; diagonal, loop, and single-spin updates
We now discuss how to generate configurations in the representation outlined above. As always in Monte Carlo importance sampling, we start from some arbitrary allowed configuration (i.e., with nonzero weight W) and from it generate a Markov chain of configurations by making changes (updates of the configuration) that are accepted or rejected according to probabilities chosen so that detailed balance is satisfied and thus the desired probability distribution P=W/Z is sampled. Using the Metropolis method, the probabilities to accept a tentative change of the old configuration into the tentative new one is

The decision of whether to accept the update if Paccept < 1 is of course made by comparing with a random number R in the range [0,1); If R>Paccept the update is rejected and the old configuration is kept.
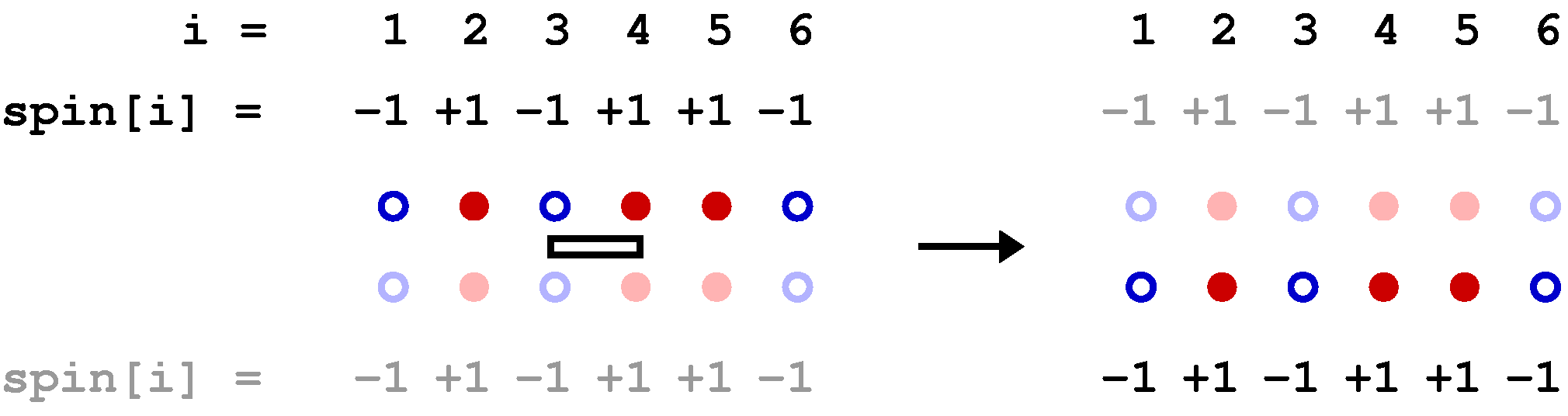
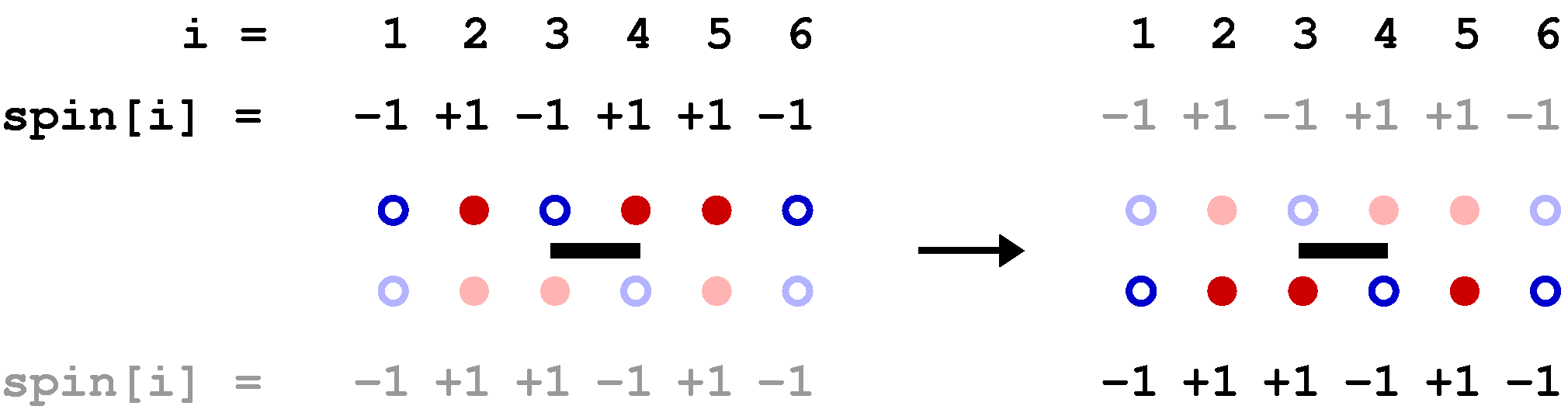
One also has to pay attention to how the tentative changes are done: With the above Metropolis acceptance probability, the probability of making a tentative change from a current configuration A to a new configuration B must be the same as the probability of making the tentative change to A when the current configuration is B. If this is not the case, then the acceptance probability has to be modified in order to correct for the imbalance. In simple classical Monte Carlo simulations, e.g., of the Ising model, the tentative probabilities are trivially equal, e.g., when randomly selecting a spin i to flip (i.e., tentatively flipping it) the selection probability is always the same; Pselect(i)=1/N. As we shall see below, this is not always the case when updating an SSE configuration.
Consider two configurations A and B, for which there is an update that can change them into each other. If the probability for selecting B when in A is not the same as selecting A when in B, one can use the acceptance probability
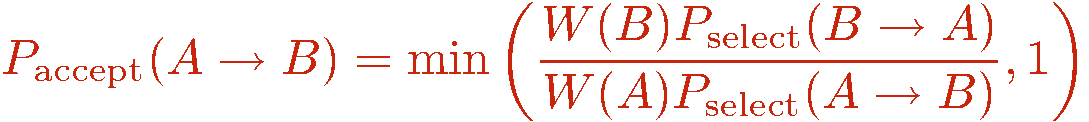
In the SSE method for the Heisenberg model, three types of updates are used, called diagonal update, single-spin flip, and loop update. The diagonal update is carried out using the representation in terms of the operator string opstring and spin[], whereas the loop update and the single-spin update make use of the linked vertex list vertexlist[], which hence is constructed before this update is carried out. We will also discuss an off-diagonal pair update update, which is typically not used because the loop update is much more efficient. We will discuss it here because it helps in understand the fine points about the loop update.
The simulation can be started from an arbitrary allowed configuration, e.g., an "empty" string (containing only elements 0, and thus n=0) of arbitrary length M and a random spin state. The cut-off M will later have to be adjusted. This will be discussed after we have described the different types of updates.
Diagonal update
The purpose of the diagonal update is to change the number n of hamiltonian operators in the sequence. The simplest way to do this is to substitute unit operators opstring[p]=0 by diagonal operators opstring[p]=2*b and vice versa. While one can always substitute a diagonal operator by a unit operator and obtain a new valid configuration, the insertion of a diagonal operator acting on a bond b requires that the spins at this bond are in an antiparallel state in the propagated state |&alpha(p)>. Hence one has to keep track of the propagated states. It is then natural to carry out the diagonal updates sequentially, starting at p=1 and propagating the state stored in spin[] as off-diagonal operators are encountered. Off-diagonal operators cannot be inserted or removed one-by one and they are thus left unchanged in this update.
We look at the three possible actions to be taken at step p of the diagonal update: At the start of the cycle of diagonal updates the spins stored in spin[] are those of the state |&alpha> = |&alpha(0)>.
Insertion of a diagonal operator: If opstring[p]=0 a bond index b is generated at random among the possible bonds b=1...B. At this stage the spin array spin[] should contain the spins of the p:th propagated state. We can then easily determine whether the diagonal operator is allowed at bond b. This bond acts on the spins s1=bsites[1,b] and s2=bsites[2,b]. The operation is only allowed if these spins are not equal, so in case spin[s1]=spin[s2] the update must be rejected and we move on to position p+1. If the operation is allowed, we have to consider the probability of actually accepting the update. The ratio of the new and old weight is very easy to calculate, as the weights depend only on n and in this update n is incremented by 1. The weigh ratio is